
La Data Science consiste en l’étude et l’analyse des données que possède une organisation, puis de leur transformation en valeur ajoutée pour le business et la stratégie de l’organisation.
Sur un projet classique, on commence généralement par explorer des données brutes. Une orientation sera nécessaire afin de prendre une direction. Il s’agira ensuite de nettoyer et consolider les données, construire des variables et établir des modèles statistiques. Le Data Scientist ou Data Analyst est très autonome dans son travail, possède des compétences diverses issues des domaines de l’informatique, des statistiques et des connaissances métiers du secteur de l’entreprise.
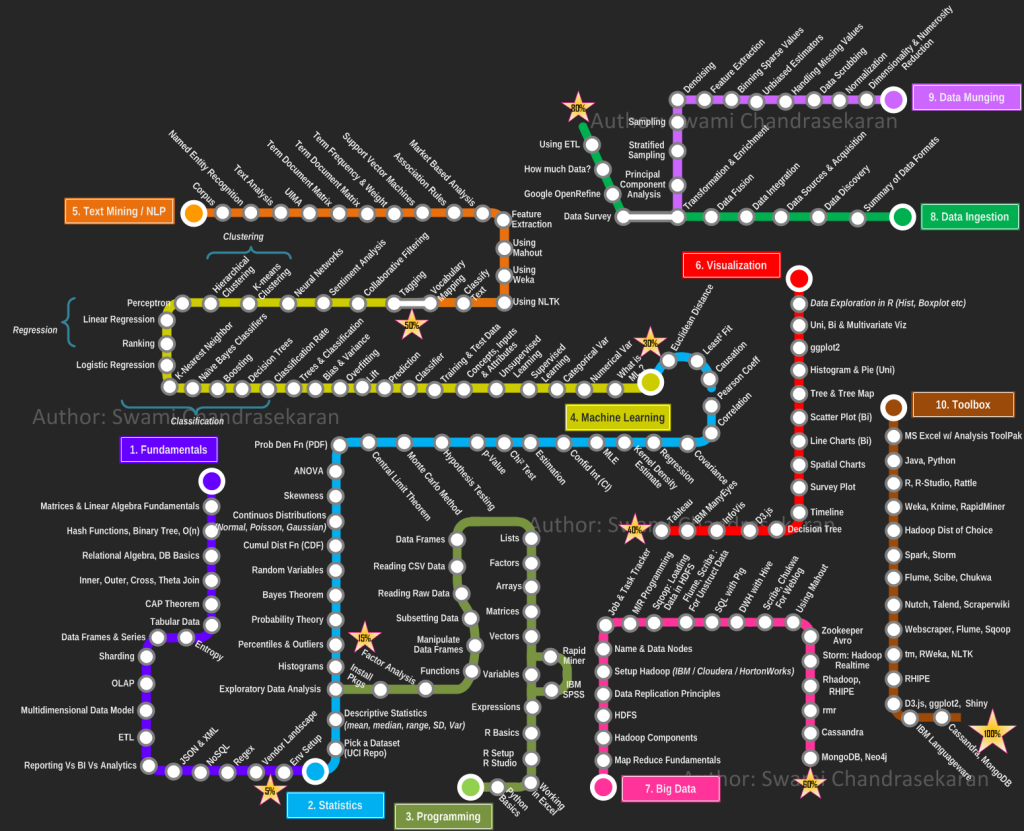
Ainsi, la Data Science requiert des connaissances dans plusieurs domaines notamment: programmation, Data Mining, Machine Learning. Il existe une carte des compétences du Data Scientist, un peu complexe à déchiffrer mais qui a le mérite d’être assez complète.
Carte des compétences du data scientist
source : Swami Chandrasekaran
La mission du data scientist en vidéo
Sa mission commence par la collecte de données brutes présentes sous différents formats.
Plus de détail sur le site des référentiels métiers.
De bonnes bases statistiques, des capacités à programmer, une approche visuelle, combinés à une vision business. Dans une seule personne.
J’ai pris beaucoup de plaisir à découvrir la Data Science. Dans cet article j’ai réuni quelques points clés pour faire ses premiers pas de façon autonome. Les formations diplomantes ne sont pas abordées ici, il s’agit plutôt de ressources pour tous les niveaux afin de mieux comprendre les enjeux du big data.
Des bases en statistiques
L’analyse de données nécessite une certaine affinité avec les statistiques et les mathématiques. Dans tous les cas, il ne faut pas hésiter à revoir les bases de lycée.
Les statistiques descriptives sont absolument nécessaires et pour tout le monde. Moyenne, médiane, variance, écart-type et intervalles de confiance font partie du quotidien de l’analyse de données.
Les représentations graphiques à maîtriser :
- Histogramme
- Box plot ou la fameuse boîte à moustache
- Diagramme en bâtons
- Diagramme de dispersion
Il est facile de trouver des articles ou des vidéos en ligne qui font des rappels sur chacune de ces notions. Wikipedia est notamment assez complet même si pas toujours le plus accessible.


Explorer, fouiller et premières analyses
En Data Science, il n’y a pas une technique mais plusieurs façons de procéder. On dit même parfois que c’est du « hack », c’est-à-dire de la bidouille. Il ne faut donc pas avoir peur d’explorer de son côté, faire à sa façon.
Pour débuter, pourquoi pas commencer par ouvrir et explorer vos données dans un tableur, Microsoft Excel ou Google Spreadsheet. Réaliser des tableaux pour résumer les données (compter les valeurs, donner la répartition, croiser les données et les informations) et des graphiques pour les visualiser sont des actions de base de tout Analyst et Data Scientist.
La fouille des données requiert un bon aperçu de l’ensemble des données. A l’échelle d’une entreprise, cela nécessite de se familiariser avec des données provenant de divers services et qui sont historisées depuis plusieurs années. Bien entendu, cela a ses limites, on ne fera pas du Big Data avec un tableur.

Exemple: une régression linéaire dans Excel
Les tableurs et notamment Excel permettent de réaliser des opérations statistiques de bases. Prenons en exemple la régression linéaire.
Tout le monde connait la régression linaire simple qui consiste à expliquer une valeur en fonction d’une autre.
C’est la fameuse équation y = ax + b. Graphiquement, la régression linéaire simple consiste à trouver la droite qui passe au plus proche de tous les points qui sont les valeurs.
Ce modèle très simple permet déjà de faire de bonnes approximations statistiques. Une régression linéaire multiple consiste à expliquer une variable en fonction de plusieurs variables. C’est également possible sur Excel, voir dans cette vidéo. Vous découvrirez aussi le coefficient R2 intéressant à étudier.
Le SQL
Les fichiers tableurs (csv, xls…) sont pratiques mais seulement pour des jeux de données peu volumineux et ne nécessitant pas trop de manipulations. Le travail sur base de données permet de s’affranchir de nombreuses limites de Excel. On ne travaille généralement plus sur un poste mais sur un serveur dédié (voire même un ensemble) et cela ouvre la possibilité au traitement de gros volumes de données, de façon simultanée et reproductible.
Il existe un langage normalisé servant à exploiter des bases de données : le SQL (pour Structured Query Language). Grâce au SQL, il est possible d’interroger la base de données afin de retrouver des données, de les croiser et de créer des statistiques sur ces données.
Le langage SQL est très utilisé dans tous les domaines, pas seulement en informatique. Biologistes, médecins, économétriciens, marketeurs et toutes les professions qui ont besoin de travailler sur des données statistiques s’y forment. Il offre l’intérêt de manier d’importants volumes de données, de faire des agrégations ou des calculs sur les données sans s’occuper de l’implémentation technique. Il n’y a pas besoin de coder des boucles, de trouver un algorithme performant, etc. C’est sans grosse difficulté pour l’utilisateur final.
Un bon cours d’introduction au SQL est disponible en ligne.
Pour une approche orientée data marketing, cette formation est bien utile SQL for Marketers.
Algorithmes de Machine Learning
Après l’exploration et la préparation vient la phase de modélisation et d’apprentissage sur les données. La vraie valeur ajoutée sur vos données est obtenue sur cette phase.
Pour débuter, il est bien d’avoir des notions des modèles statistiques et algorithmes d’apprentissage automatique (Machine Learning en anglais) utilisés sur cette phase. Pour la connaissance parfaite des techniques (et des formules mathématiques), on laissera cela à un expert Data Scientist.
Voici trois techniques de modélisation ou d’apprentissage statistique que l’on rencontre couramment :
- La régression permet d’expliquer une variable numérique en fonction d’autres variables. A noter qu’il existe plusieurs types de régressions (linéaire et non linéaire, simple et multiple, …).
- La classification range des éléments dans des classes. Très souvent, la classification est binaire (c’est-à-dire qu’il y a seulement deux classes). Par exemple, est-ce que l’un de mes clients va « churner » (arrêter son abonnement) dans les 6 prochains mois? (réponse oui/non) Il existe plusieurs algorithmes de classification dont l’apprentissage par arbres de décision.
- Le clustering consiste à diviser un ensemble d’éléments en groupes homogènes. Par exemple, il est possible de diviser les visiteurs d’un site internet en différents groupes en fonction de leur comportement via une analyse des logs (les lecteurs habituels, ceux qui viendront une seule fois, les bots, etc.). Un algorithme assez connu est celui des k-means.
Les ressources françaises pour apprendre ces techniques sont un peu moins nombreuses. Je vous conseille de vous tourner vers un ouvrage anglais ou vers un MOOC sur les plateformes Coursera.org et edX.org. Le parcours Data Science propose plusieurs petits modules également.
Vous pouvez aussi consulter la présentation Introduction au Data Mining et Méthodes Statistiques de Giorgio Pauletto qui résume bien ce que nous avons vu jusqu’à présent.
La visualisation
La visualisation que l’on appelle parfois data-viz intervient tout le long d’un projet sur la donnée afin d’accompagner la compréhension. Construire des graphiques ou autres visualisations aide à appréhender les données et les chiffres.
Surtout, la data-viz permet sur les phases finales de restituer, expliquer et mettre en valeur le travail de l’Analyst ou du Data Scientist. Cela participe à la retransmission de l’information.
Là, les outils accessibles facilement sont plutôt nombreux. En plus des solutions logicielles (citons seulement Excel et Tableau), de nombreux sites en lignes permettent des créations en quelques minutes. Un exemple parmi tant d’autres : RAW.
Par contre, la création de visualisations animées est plus compliquée. Il faudra probablement faire appel à du JavaScript et à la librairie D3.js.

Python, R et Hadoop
Il y a des incontournables aujourd’hui dans l’univers de la Data Science. Cela concerne notamment la maitrise du langage R spécialisé dans l’analyse statistique et/ou du langage Python et ses librairies associées (Pandas, Scikit-learn…). (Si vous hésitez entre les deux langages, cet article est pour vous.)
La courbe d’apprentissage d’un langage de programmation est un peu plus ardue mais un bon Data Scientist doit être aussi un bon programmeur. Cela permettra de s’affranchir de toutes limites dans la collecte et la préparation des données, dans la création des variables et surtout de générer et comparer de nombreux modèles personnalisés.
Pour travailler sur de gros volumes de données, Hadoop est devenu un standard. Il est indispensable de maitriser le framework dans un cadre professionnel. Avec Hive, il est possible de manipuler des données sur Hadoop via des requêtes SQL.
Pour cet apprentissage plus technique et qui ne conviendra pas à un débutant, les ouvrages en langue anglaise seront d’un bon secours. Regardez du côté des éditeurs Packt et O’Reilly.
Par où commencer
Données réelles
S’entrainer avec des données
J’espère que ces quelques pistes vous apporteront un premier éclairage. C’est très vite prenant une fois que l’on a commencé.
Pour progresser, rien de mieux que de s’entrainer sur des données. C’est justement ce que propose la plateforme DataScience.net : des concours sur des cas concrets (dataset fournies par les entreprises).
Il suffit d’avoir Excel ou un autre éditeur équivalent pour débuter. Voici quelques exemples.



AXA. L’objectif d’AXA France est de disposer de modèles prédictifs permettant d’appréhender le comportement des clients selon différentes situations de marché (évolution des taux du marché, des prix de l’immobilier…). Plus d’infos
RTE. La société réalise quotidiennement des prévisions de consommation d’électricité qui permettent d’assurer à tout instant l’équilibre entre l’offre et la demande d’électricité et, ainsi, de garantir la sûreté du système électrique.
L’objectif du challenge est d’effectuer une prévision déterministe à court terme de la consommation nationale et régionale d’électricité en France. Plus d’infos
SNCF. Le challenge consiste à construire un modèle permettant d’estimer efficacement le nombre de voyageurs montant par gare pour un jour de semaine, dans les gares SNCF du réseau Ile-de-France, à partir de données open data caractérisant la gare d’un point de vue SNCF (nombre de lignes, nombre de trains par jour, services en gare, etc.), mais également de données externes (caractéristiques socio-démographiques de la ville, présence de transports urbains, etc.). Plus d’infos
Kaggle
Autre plateforme de challenges data science

Les plateformes de challenges mettent à disposition des données réelles, c’est très simple d’y participer :
- Choisissez votre challenge
- Téléchargez les données (vous aurez besoin de deux jeux de données pour évaluer votre modèle, et l’échantillon de test sur lequel vous testerez votre modèle)
- Estimez les résultats obtenus par votre modèle sur l’échantillon de test avant de l’envoyer.
A travers ces quelques exemples, on peut voir que la data est omniprésente dans notre vie quotidienne, souvent même sans qu’on le sache.
Pause musicale
Un algorithme a conçu cette playlist musicale
La data science est partout, même dans la musique, ce qui rend cette discipline captivante et ludique. J’espère que cet article vous aura donner des pistes. N’hésitez pas à me contacter, je serais ravi d’échanger avec vous sur ce sujet.
Taveng
Merci à Swami Chandrasekaran, Jerese, Udemy, Openclassroom, Datasciencecentral, ENSAE, Genes.