Les data sont sources de créativité ! Spotify le prouve en jouant la proximité dans une campagne internationale.
Depuis son lancement en Suède en 2008, Spotify a creusé l’écart. Le service de musique en ligne est maintenant disponible sur 60 marchés et compte plus de 100 millions d’utilisateurs actifs dont 40 millions d’abonnés payants.
La marque a lancé fin 2016 la plus importante campagne jamais réalisée. Elle a été déclinée dans 14 pays au total : France pour commencer, puis Etats-Unis, Royaume-Uni, Argentine, Australie, Brésil, Canada, Allemagne, Indonésie, Mexique, Nouvelle-Zélande, Philippines et en Suède pour une seconde vague.
L’idée : fouiller dans les data pour y découvrir les plus étranges secrets d’écoute de leurs utilisateurs. Le concept a été développé en interne.
Datacenters de Spotify
Cloud
Il est difficile d’imaginer l’infrastructure nécessaire pour traiter le volume de data que gère Spotify.
La société envisage de migrer presque l’ensemble de ses workloads de back-office, hébergées en mode privé, vers la Google Cloud Platform. La firme a d’abord envisagé de construire son propre datacenter, mais a finalement revu sa position pour des raisons de coûts et de compétences nécessaires au projet. Elle s’est tournée vers Google pour accroître ses capacités en matière de Big Data. Spotify opte ainsi pour l’infrastructure Google qui permet de pousser un flux de données mis à jour en temps réel vers ses utilisateurs.
La société dispose de dizaines de milliers de machines réparties dans 4 datacenters dans le monde. L’objectif est d’avoir rapidement une grande partie de l’infrastructure installée sur la Google Cloud Platform. Un petit groupe d’utilisateurs a déjà accès aux services de la plateforme.
Google est bien en avance lorsqu’il s’agit de traiter de grandes quantités de données.
BigQuery, le service de base de données analytique, fait la différence, mais Spotify teste aussi d’autres outils Big Data de la marque : Dataflow, le service de traitement de données en streaming ou en batch, et BigTable, qui pourrait potentiellement remplacer Cassandra et les outils de gestion que cela demande.
Au fur et à mesure que le marché du Cloud public gagne en maturité, les fournisseurs souhaitent chasser les préoccupations des entreprises en matière d’environnements multitenants et rassurer sur leurs capacités à soutenir des processus d’entreprise. Même si Google compte parmi ses clients des Coca-Cola ou encore Macy’s, il est souvent perçu comme n’ayant pas la même portée auprès des entreprises qu’AWS ou Microsoft – une image que Google tient à changer.
En fait, Spotify est aussi un client clé pour Amazon, qui a fait de la société une étude de cas de ses services. Spotify continuera d’ailleurs à utiliser Amazon Simple Storage Service et CloudFront pour la distribution de contenu, cela signifie donc que le stockage et le traitement de l’audio sera maintenu sur AWS, mais la partie principale de l’infrastructure, dédiée aux metadata des playlists, aux recommandations et à la recherche dans les catalogues, migrera vers Google.
Spotify améliore notre culture musicale (?)
Algorithme de recommandations
Ces systèmes utilisent un réseau de neurones artificiels comme méthode d’apprentissage. Pour comprendre comment un programme peut être capable d’apprendre sans être supervisé, voici un exemple simple avec k-means, une méthode utilisée pour le partitionnement de données (clustering).
Imaginez que vous bossez chez Spotify et qu’on vous demande de développer une fonctionnalité de recommandations de musique. Une proposition est pertinente si elle permet à l’utilisateur de découvrir un nouvel artiste qu’il va adorer et ainsi l’inciter à renouveler son abonnement.
Vous disposez donc d’un énorme jeu de données et d’une multitude de façons de les regrouper : par genre (hip-hop, classique, rock…) par auteur, par période, etc. Pour être plus efficace qu’un simple algorithme de “matching” nous allons laisser le système trouver seul des caractéristiques communes à partir d’un très grand volume de données.
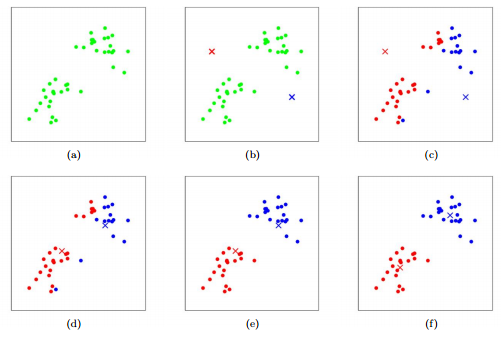
L’idée est de laisser le système grouper les musiques et les utilisateurs selon des critères qu’on ne connait pas encore (des corrélations cachées), mais que nous pourrons ensuite utiliser pour notre moteur de recommandations. Lorsqu’on représente un nuage de points en 2D, il est très simple pour nous (humains) de distinguer visuellement 2 paquets homogènes de points dès l’étape (a)
Pour copier notre très bonne capacité associative, l’algorithme K-means utilise une stratégie de machine learning: on place de manière aléatoire 2 points (x rouge et x bleu) (étape b), on découpe le nuage de points en 2 groupes en suivant cette règle. Tous les points qui sont les plus proches de la croix rouge sont colorés en rouge et tous ceux qui sont plus proches de croix bleue sont colorés en bleu (étape c). À ce stade, le résultat n’est pas top, on va déplacer nos 2 croix au centre de gravité de chaque groupe de couleurs (étape d). On répète l’opération, répartir les points entre chaque croix (étape d), replacer nos croix (étape e) jusqu’à l’obtention d’une convergence, c’est à dire une stabilisation des centres (l’algorithme a cessé de s’améliorer) (Cette video explique très bien la méthode).
Imaginez maintenant que le nuage de points représente des utilisateurs sur une multitude d’axes (dimensions) issus de données comportementales (ses notes, ses achats, ses commentaires, …). Comme le montre cette vidéo, on arrive à des résultats qui parlent d’eux même.
Pour faire le lien avec notre mission imaginaire chez Spotify, une bonne stratégie pourrait être de proposer à un nouvel utilisateur du cluster “pitchounette”, des titres qui fonctionnent très bien avec la population à laquelle elle appartient. Ensuite tout est une question de dosage et d’ajustement du poids (= l’importance) qu’on donne aux critères. Il faut croiser minutieusement les résultats de milliers de critères issus de ces classes et c’est là que ça devient très complexe… On peut s’appuyer sur des spécialistes de la musiques, sur des analyses acoustiques, sur un historique de navigation, sur les écoutes récentes, récurrentes, etc… Plus on a de data (90% des données dans le monde ont été générées ces 2 dernières années selon IBM) et plus on maitrise le domaine qu’on analyse (Google pour l’information, Netflix pour les films, …) plus on arrive à faire de bonnes prédictions.
Vous connaissez sans doute les daily mix proposés par la plateforme musicale. Pour finir voici 2 vidéos expliquant comment Spotify recommande Muse après avoir écouté Artic Monkeys et Chopin.